Crashkurs CQRS
12.03.2014

Command Query Responsibility Segregation (CQRS) und Domain-Driven Design werden in der Community schon länger leidenschaftlich diskutiert. Belastbare, einstimmige Antworten der üblichen Evangelisten sind jedoch nur schwer zu finden. Im Vergleich hängt die Nicht-Microsoft-Welt gefühlt hinterher.
Was aus unserer Sicht fehlt ist eine ausreichende Menge konkreter Beispiele, an denen man lernen und dieses Architekturprinzip diskutieren und weiterentwickeln kann. Besonders interessant ist es unserer Meinung nach erst einmal komplette Durchstiche zu sehen, bevor man sich in den Weiten von Detaildiskussionen verliert.
Der Ursprung: vom Kleinen...
CQRS hat seine Wurzeln in einem Prinzip des Objekt-orientierten-Designs namens CQS , das Bertrand Meyer wie folgt auf den Punkt bringt:
Das Fragen einer Frage sollte nie die Antwort verändern.
Praktisch bedeutet das eine strikte Zweiteilung von Code in Dinge, die Daten verändern (Commands) und reine Abfragen von Daten (Queries).
zum Großen
Hebt man diese Teilung auf die Ebene verteilter Unternehmensanwendungen, fällt auf, dass sich die nichtfunktionalen Anforderungen von Command- und Query-Anteilen auch auf dieser Ebene stark unterscheiden (Tabelle 1). Während Commands eine hohe Konsistenz und normalisierte Datenspeicher mögen, ist für Queries eine (kurzfristige) Inkonsistenz kein Problem und denormalisierte Daten optimal. In Sachen Skalierbarkeit zeigt sich, dass der Gesamtanteil an der Systemlast von Queries im Normalfall höher ist als der von Commands. Die Herausforderungen in Sachen Skalierung liegen damit eher auf der lesenden Seite und weniger auf den schreibenden Operationen. Dies gilt vor allem bei webbasierten Systemen. Versucht man, die Anforderungen mit einem einzigen Architekturansatz zu lösen, gerät man in Probleme. Im Falle der klassischen Drei-Schichten-Architekturen ist dies vor allem ein exponentiell steigender Bedarf an immer höherer Datenbankleistung. Ein teurer Spaß, der vor allem irgendwann auch an die Grenzen des technisch Machbaren stößt.
Anforderungen an Konsitzenz an Datenspeicherung an Skalierbarkeit von Commands Transaktionen bei hoher Konsistenz wesentlich einfacher zu handhaben. Normalisierung besser (nahe 3NF). Oft nur geringer Prozentsatz von Commands an Gesamtlast. von Queries Kurzfristige Inkonsistenz oft kein Problem. Denormalisierung besser. Oft hoher Prozentsatz von Queries an Gesamtlast.
Jedem das Seine: CQRS als Architektur-Prinzip
CQRS tritt mit dem Anspruch an, dem unterschiedlichen Charakter von Command- und Query-Anteilen einer Anwendung Rechnung zu tragen (Abb. 1).
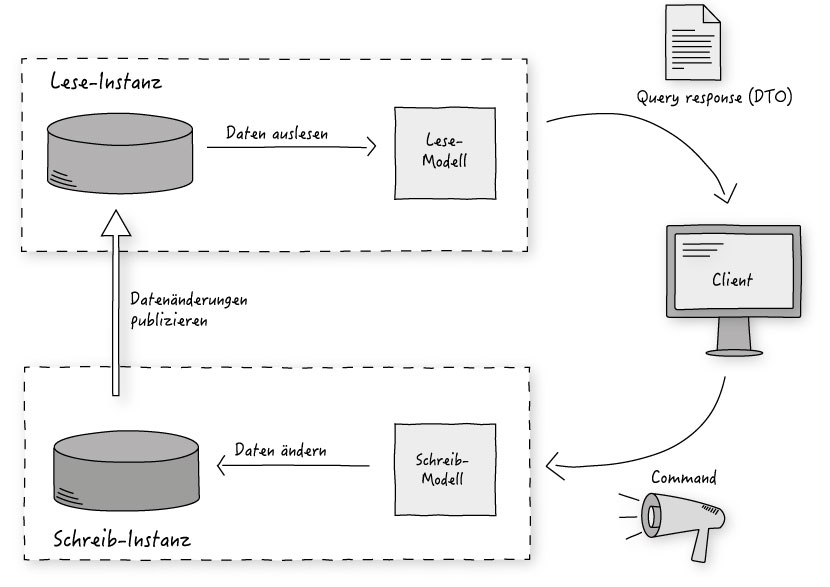
Das System wird in lesende und schreibende Instanzen geteilt. Möchte ein Client etwas tun, das Daten verändert, setzt er Kommandos ab. Eine Schreib-Instanz entscheidet, ob die gewünschten Änderungen durchgeführt werden können und handelt entsprechend. Braucht der Client Daten, fordert er diese von einer Lese-Instanz durch eine Query an. Die Instanz liefert die gewünschten Daten dann in Form eines DTOs zurück.
Eine Besonderheit des Prinzips ist, dass jede der beiden Seiten konzeptuell eine eigene Datenquelle besitzt. Im Falle relationaler Datenbanken kommt auf der Lese-Seite ein denormalisiertes Datenmodell zum Einsatz, während die Schreib-Seite auf normalisierten Daten arbeitet. Die Übersetzung von einem Modell ins andere liefert eine eigene Komponente, die Änderungen an die Lese-Instanzen liefert.
An dieser Stelle werden bereits Möglichkeiten in Sachen Skalierbarkeit deutlich: trennt man die Datenquellen tatsächlich, skalieren die Seiten unabhängig von einander. Braucht man mehr Power, schafft man zusätzliche. Dies geschieht zum Preis einer Zeitverzögerung bei der Herstellung der systemweiten Konsistenz nach Änderungen von Daten. In vielen Fällen sind diese Latenzen jedoch weder technisch noch fachlich ein Problem.
CQRS in Practice – ein Fallbeispiel
Um ein wirkliches Gefühl für CQRS zu bekommen, muss man sehen wie es in der Realität funktioniert . Wir stellen zu diesem Zweck im Folgenden einen 30.000-Fuß-Flug über ein prototypisches System aus unserer bisherigen CQRS-Reise vor.
Um uns den technischen Details widmen zu können, betrachten wir ein einfaches Produktivitäts-Werkzeug, das einen mobilen Client besitzt und mit einem zentralen Backend kommuniziert.
Neben weiteren Features, kann der Benutzer eine Aufgabenliste verwalten und in diesem Kontext Aufgaben (engl. tasks) als abgeschlossen kennzeichnen (engl. mark as complete).
It all starts at the client …
Der User sitzt vor seinem Tablet und entdeckt eine Aufgabe in seiner Todo-Liste, die er als "erledigt" markieren möchte. Schauen wir im Folgenden, was passiert, nachdem er den Haken an der entsprechenden Stelle gesetzt hat.
Listing 1
public class TaskDTO { private TaskId id; private TaskStatus status; private String description; [...] }
Am Ende führt alles auf eine Änderung des Status-Attributes eines Task-Eintrags in der Persistenzschicht hinaus. In “klassischen”, stark datengetriebenen Anwendungen ohne CQRS läuft das gewöhnlich wie folgt ab:
Abfragen als auch Änderungen verwenden das gleiche Modell: ein Objekt wird vom Server geholt, am Client geändert und wird wieder zum Server gesendet (z. B. in Form eines DTOs). Warum ein Datensatz geändert wurden (hier: Änderung des Status) ist später nicht mehr re¬kon¬s¬t¬ru-ier¬bar. Diese Intention des Users zu bewahren kann aber extrem nützlich sein. Beispielsweise, um vollständige Nachvollziehbarkeit zu gewährleisten, aber auch um fachliche Konflikte auflösen zu können, die ohne dieses Wissen zum (irrtümlichen) Abweisen einer Änderung führen würden.
Kurzes Beispiel: Angenommen die Nutzerin hat auf ihrem Smartphone die Beschreibung einer Aufgabe geändert, während Sie offline war. Zu einem späteren Zeitpunkt setzt sie nun den Status dieser Aufgabe auf ihrem Tablet auf “fertig”. Kurz darauf kommt das Telefon aus dem Funkloch heraus. Ein klassischer Konflikt, der ohne die Speicherung der Intention der Änderungen nicht automatisch auflösbar wäre, da wir nur wissen, dass eine Änderung am selben Datensatz stattgefunden hat. Wenn wir die Intentionen der jeweiligen Änderungen kennen und spezifizieren, dass eine nebenläufige Änderung von Status und Betreff keinen Konflikt darstellt, können wir diese Situation automatisch auflösen und beide Änderungen durchwinken.
Ein solches Vorgehen macht CQRS möglich: Ausgangspunkt ist zwar auch hier ein DTO, das vom Server erfragt wurde (siehe Listing 1). Statt die Änderung direkt am DTO vorzunehmen und es wieder komplett zum Backend zurückzusenden, wird jedoch eine CommandMessage erzeugt, die die zur Änderung notwendigen Informationen enthält und zusätzlich die oben angesprochene Intention konserviert (siehe Listing 2).
Listing 2
@CommandMessage public class MarkTaskAsComplete { private TaskId id; public MarkTaskAsComplete(TaskId taskId) {...} }
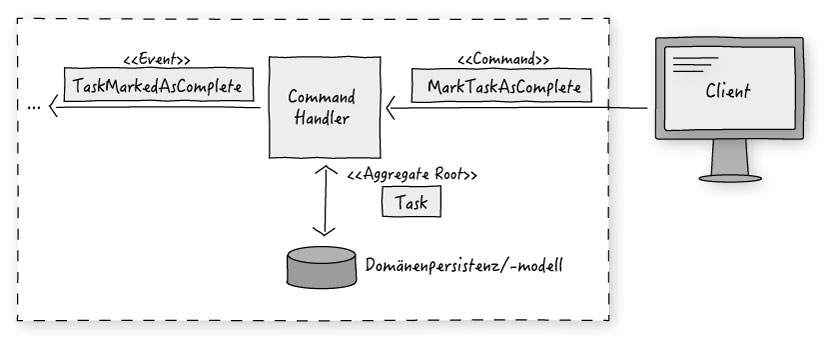
Die CommandMessage wird zum Backend gesendet und von einem entsprechenden CommandHandler ausgeführt bzw. abgewickelt (Listing 3). Die Auswahl des zuständigen Handlers kann dabei zum Beispiel an Hand der Klasse des Kommandos erfolgen oder über Annotationen und Reflection Mechanismen.
Listing 3
public class TaskCommandHandler { @Autowired TaskRepository tr; @Autowired EventBus eb; @CommandHandler public void markTaskComplete(MarkTaskAsComplete commandMessage) { Task t = tr.findOne(commandMessage.taskId()); t.markComplete(); tr.save(t); eb.publish(new TaskMarkedAsComplete(t.id())); } @CommandHandler [...] }
Der oder die gefundenen Handler suchen sich die Informationen für die Ausführung des Kommandos zusammen, führen die entsprechenden Aktionen auf dem Domänenmodell aus, und veranlassen die Speicherung der Änderungen in der Persistenz-Schicht der Schreib-Instanz. Querliegende Transaktions- und Sicherheitsaspekte würden ebenso an dieser Stelle behandelt, sind der Übersichtlichkeit wegen aber ausgelassen.
Über das, in Abbildung 2 angedeutete, Event würde schließlich die Datenänderung an das Lese-Modell propagiert . In einem ersten Schritt werden diese Events von uns aber lediglich gespeichert und für Aspekte der Nachvollziehbarkeit (Bugfixing, Audit, …) herangezogen. Die Idee, die sich hinter diesem Vorgehen verbirgt, nennt sich Event-Sourcing . Diese Büchse zu öffnen muss aber einem späteren Artikel vorbehalten bleiben.
Und ab ins Domänenmodell...
Schauen wir uns nun noch die “letzte Meile” der angesprochenen Schreib-Instanz an (Abbildung 3). Der CommandHandler liegt in der Anwendungs-Service Schicht und greift sowohl auf die Domänen- als auch auf die Infrastruktur-Schicht zu, um seine oben beschriebenen Aufgaben zu erfüllen.
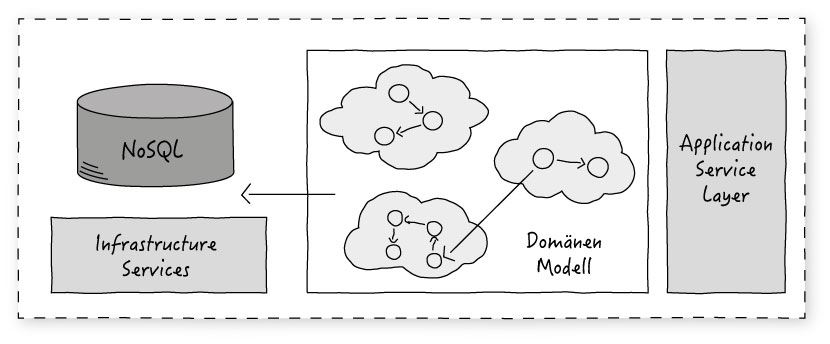
Der Aufruf von markTaskComplete() des Task Domänenobjekts setzt dessen Status auf COMPLETE, abschließend werden die aktualisierten Daten in einer NoSQL Datenbank gespeichert.
Listing 4
// (0) Klasse des Domänenmodells nach DDD @AggregateRoot public class Task { // ... private TaskStatus status; public void markComplete() { this.status = TaskStatus.COMPLETE; } } // (1) MongoDBRepository Interface public interface TaskRepository extends MongoRepository <Task, TaskID> { } // (2) Spring Configuration @Configuration @EnableMongoRepositories class ApllicationConfig extends AbstractMongoConfiguration { // ... }
An dieser Stelle gehen wir davon aus, dass zu diesem Zweck die MongoDB -Anbindung von SpringData zum Einsatz kommt. Nett: einmal mit @EnableMongoRepositories im Spring-Kontext aktiviert, braucht nur das Interface selbst geschrieben zu werden. Die Implementierung der Methoden wie z. B. findOne(...) oder save(...) übernimmt dann Spring.
Design-Erläuterungen
Die geschilderte Situation ist typisch für die Anfangszeit eines Projekts. Die Datenquellen für Commands und Queries sind noch nicht getrennt, sondern in einer NoSQL-Datenbank zusammengeführt. Dieses Vorgehen hat zwei Vorteile, die vor allem in einer frühen Phase der Entwicklung zum Tragen kommen:
Zum einen verringert es den Anfangswiderstand in der Entwicklung, da durch den NoSQL-Ansatz die Notwendigkeit entfällt, SQL-Schemata zu entwickeln. Daumenregel: Ein DDD-Aggregat entspricht einer NoSQL-Collection.
Zum anderen entfällt die Komplexität der Entwicklung einer Publisher-Komponente zur Kommunikation von Datenänderungen an die Lese-Instanzen, ohne sich eine Weiterentwicklung des Systems in diese Richtung zu verbauen (z B. durch die Verwendung von Event-Sourcing). Der Grundstein für diese Erweiterung ist durch die Erzeugung und Speicherung von Events durch den CommandHandler bereits gelegt.
Zu einfach…?
Im geschilderten Beispiel konnten wir viele Aspekte nur anreißen bzw. mussten viele, zum Teil extrem wichtige Details, ganz auslassen, um einen vollständigen Durchstich einer CQRS-Anwendung beschreiben zu können. Die Notwendigkeit so vorzugehen ist Symptom einer der größten Herausforderungen beim Einsatz von CQRS: die enorme Lernkurve durch die vielen beteiligten Ansätze und Prinzipien.
CQRS, DDD, Event Sourcing und (asynchrone) Domain Events sind zwar in der Theorie unterschiedliche Ansätze, in der Praxis jedoch kaum von einander zu trennen. In der Summe bilden sie ein mächtiges Werkzeug, das verspricht viele der gängigen Probleme in klassischen Architekturen handhabbar zu machen. Um zu dieser Summe zu gelangen müssen jedoch erst einmal die Einzelkonzepte verstanden und zu einem pragmatischen Gesamtkonzept verwoben werden.
Diese Aufgabe stellt nicht nur einen geistigen Aufwand dar. Die vorgestellten Konzepte sind in der präsentierten Form noch mit wenig Aufwand selbst zu implementieren, stellen jedoch Vereinfachungen dar, die schnell an praktische Grenzen stoßen. Für komplexere Anwendungen muss schnell auf existierende Frameworks und Technologien zurückgegriffen werden, die wiederum auch erst einmal verstanden und sinnvoll kombiniert werden wollen (für die Java/Scala-Welt z.B. Axon, Eventsourced, Akka, Vert.x, ...).
Was bleibt
Obwohl in der Gemeinde lange diskutiert und zum Teil als Allzweckwaffe gefeiert , sollte man sich gut überlegen ob CQRS/DDD für die eigene Problemstellung die richtige Wahl darstellt. Dass der Ansatz ein Konglomerat aus unterschiedlichen Prinzipien darstellt kann man bei dieser Überlegung auch als Vorteil gelten lassen: CQRS oder Teile daraus lassen sich gut und sinnvoll auch in Teilbereichen eines Systems einsetzen.
Wir sind davon überzeugt, dass die Ideen hinter CQRS/DDD einen wichtigen Bestandteil modernen Software-Engineerings ausmachen, die jeder Entwickler kennen sollte. Und sei es nur aus dem Grund, eingeschliffene Denkmuster zu hinterfragen und neu zu bewerten. Darüber hinaus bietet der Ansatz für viele Anforderungen komplexer Systeme Lösungsvorschläge, die uns in unserer täglichen Praxis geholfen haben.
Die autoritative Antwort auf die Frage: "CQRS: Ja oder nein?" steht für viele konkrete Klassen von Problemen und Situationen des Entwicklungsalltags noch aus. Ein "Warum eigentlich nicht?" klingt aber mehr als plausibel.
Lernen wir weiter, indem wir was tun.
Carsten Röttgers und Daniel Pieper sind Gründer von minnits, der Assistainment Plattform für Professionals, und bauen seit über 17 Jahren Software-Produkte. Zusammen mit der agido Ventures GmbH entwickeln Sie derzeit ein Produktivitätswerkzeug der nächsten Generation.

